Table of Contents
New Assistants API
The Assistants API, released on OpenAI’s first DevDay, received a lot of attention. However, looking closer, we can see that this was an obvious move for OpenAI. There has been a clear rising interest in ‘Retrieval Augmented Generation (RAG)’ and ‘Autonomous Agents’ in the industry and open-source community. Companies tackling these problems, like Langchain and Pinecone, have crossed the $100 million valuation at record speeds. This move could also be part of OpenAI’s strategy of locking in users. The Assistants API streamlines a large chunk of the functionality provided by libraries like Langchain, but admittedly at a cost, not just in terms of price but also in terms of customizability and observability.
I cover all the concepts in this article in more depth in following video but if you want a nice quick read then this article is for you!
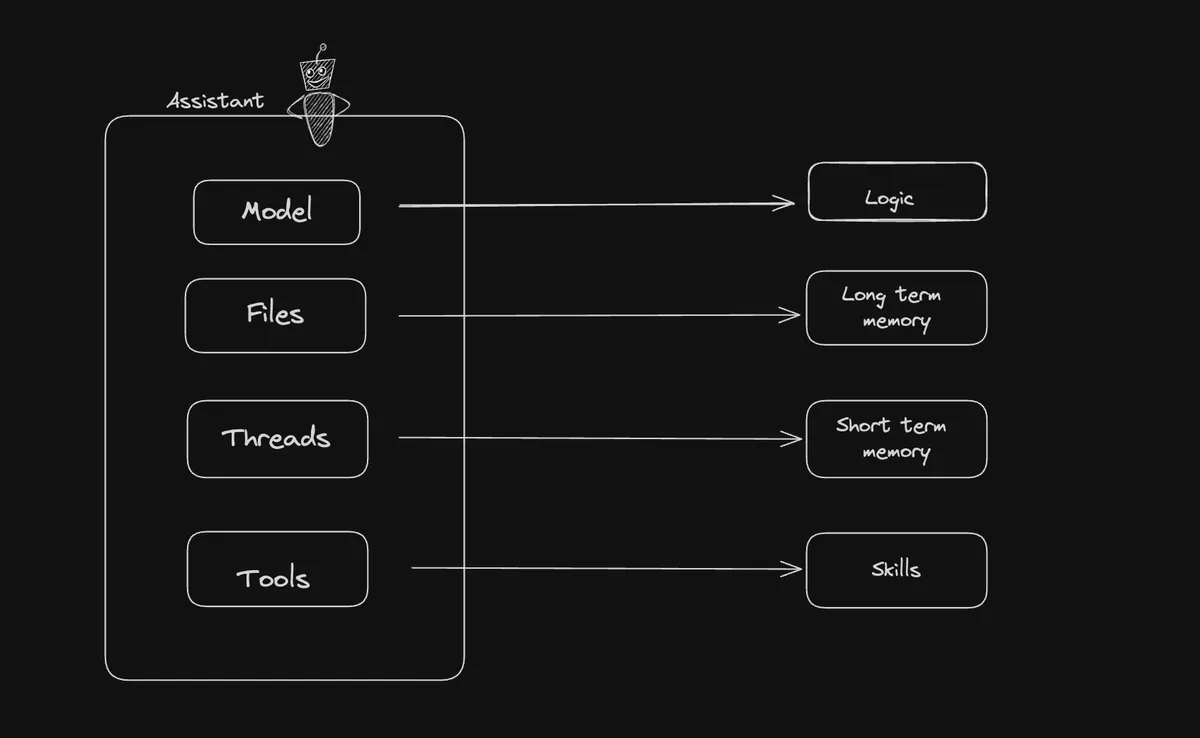
Core Componenents
-
The Model - The Brain of the Assistant: Choosing between models like GPT-3.5 or GPT-4 can be likened to selecting a brain for your Assistant. GPT-4, being more advanced, offers a “smarter brain” but comes with higher costs.
-
Files - The Long-Term Memory: These are akin to books you hand to your Assistant. It uses these files to pull information and respond to queries, effectively serving as its long-term memory.
-
Threads - The Short-Term Memory: Threads represent the Assistant’s ongoing conversations, functioning as its short-term memory. They keep track of the dialogue flow but are not retained indefinitely, especially when multiple conversations are happening.
-
Tools - The Skills and Abilities: These are the functionalities that you can either use from OpenAI or develop yourself, like a code interpreter or a business-specific calculator. Tools enhance the Assistant’s ability to perform tasks and provide responses.
The Assistant Capabilities
The Assistants API offers three core capabilities:
-
Document Retreival: You can provide the assistant with files ahead of time and OpenAI will handle indexing this data. OpenAI will allow up to 512MB files. The algorithm used for retrieval is described in OpenAI documents as follows:
- If the document is small enough, include it in the context,
- Otherwise openAI handles generating the embeddings, vectordb, and chunking for you.
Being able to pass documents and using retrieval with GPT isn’t something new. Using libraries like langchain or custome code for generating embeddings and doing retrieval has become a mainstream approach, although not perfect, it works pretty well. It’s not clear yet if using the Assistants API will provide better results than doing this on your own servers since:
- You lose observability and control over what ends up in the context. OpenAI hiding these pieces makes debugging and fixing an assistant behaviour very hard.
- The current Assistants API algorithm seems pretty simple which might not justify the extra cost required for using the retrieval API at $0.20/GB per assistant per day which can add up really quick.
-
Taking Actions: Actions basically allows you to define tools, which are usually other apis like Dall-E, or your own custom tool (e.g a calculator for your business). This capability is already provided in the vanilla GPT4 api and have been made faster with the new parallel function callings ability. The only thing the assistant provides on top of the GPT-4 api is premade tools, which currently only include the
Code Interpreterbut will likely be expanded in the future. -
Thread managment: A thread in the context of the Assistant is essentially a conversation. It’s a straightforward process where you send a message, receive a response, and continue the dialogue. OpenAI with the Assistants API is offering to directly manage your conversation so that you stay within context length. It’s not clear if OpenAI is doing any magic here as opposed to just truncating when the conversation is larger than the context.
Quality of life at what cost?
One big problem I see with the Assistants API is that this blackbox approach in an API could make customization, observability, predicatbility, debuging, and managing costs a nightmare. You are still billed based on the number of tokens in your context for every query but now you have no control over that. You don’t know what was included in the context, you don’t know how the decisions to what’s in the context were include, and you don’t know how much it will cost until it’s too late. If you aren’t getting the results you want, you can’t tell if the problem is in the retrieval, thread managment, GPT4 itself, or anything in between.
Conclusion
The Assistants is definelty a powerful and useful API that can speedup your efforts and reduce the time you need to get something working and production ready. However, it’s worth knowing that everything provided by the Assistants API was possible before with the Chat Completion APIs with the help of some libraries or your own custom code at a possibly lower costs and more customization and observability. The more you need to scale this, the more relevant these concerns will become.
If you found this helpful, consider subscribing for more insights and let me know what other topics you’d like to explore. Thank you for reading!